I went to the first CoreOS Fest this week and the following photo, of which I am clearly the main subject, proves it!

Now that that’s out of the way, here are my notes from that event.
Container all the things!
Oh yes, that reminds me. Before I talk about CoreOS Fest, let’s first establish a common ground on this containerization thing. There appears to be some confusion about what it is and whether it makes VMs obsolete (it does not).
My favorite explanation of containers comes from a Reddit comment which I include below for your convenience. Go ahead, it’s a fun read.
Think of every process on the machine as a 5-year old. If you have a bunch of them, they’re eventually going to start fighting. Ever seen 5-year olds fight? It’s stupid:
“He’s standing near me and I don’t like it!”
“I don’t want her to make that noise!”
In the context of a process on Linux, you can think of this as two server processes that both want to listen on the same port, or write a config file to the same place. And here you are, thinking “God dammit you guys, grow the fuck up and share. If you can’t handle this, wait til your first interaction with the DMV.” But they will never share, because they’re five years old. They’ll just whine at each other to the point where you have to physically separate them just to preserve your own sanity.
One way to physically separate a dozen five-year-olds is to build a dozen houses, and give them each a house. This is like running a separate physical machine for each process. Yes, it solves the problem, but it’s expensive and wastes resources. So then you try a Virtual Machine inside one physical host. If we’re talking about separating five-year-olds, this is like turning one house into a bunch of apartments, one for each five year old. This allows for maximum configurability. Each five year old can set the thermostat at whatever temperature is comfortable. Sure, they don’t have as much space as they would if they had the whole house, but at least they’re contained. They’re not really aware of each other, but generally, they’re happy.
But if you’re Mom & Dad, this is just silly. Do you really need one separate kitchen for each five-year-old? No, that’s overkill. One kitchen is enough. Do five year olds really need to set the thermostat as they please? No, they’re fucking five. Plus, I’m the parent, I pay the heating bill, and the thermostat isn’t going over 57 degrees all winter, God dammit!
So what’s the solution? You give each kid a magic pair of glasses that let them see everything but each other. They’re all walking around the house, only aware of their own existence. Ah, but what if they both want to play with the same toy? Simple, buy the one same toy for each kid. A lot easier than building a house for each kid. In reality, they’re only going to conflict over a very small number of things in the house, so you can replicate those things, and the five year olds will be none the wiser.
This is what LXC is. It lets processes think they have complete run of the machine, but a very lightweight hypervisor keeps them separate. They’re all still running on the same kernel, but they don’t know it. An LXC Container is a collection of files that represents the minimum set of “toys” the processes might fight over. It’s a bit more advanced, though. You can, for example, run a RedHat LXC Container inside an Ubuntu kernel. As long as your processes don’t have explicit expectations about the kernel, you’re fine. And most of the time, processes don’t have such expectations. LXC is kind of tricky to configure, though. Docker is a layer over LXC to make it really easy to use these containers.
ADDENDUM: Docker has since moved from LXC to their own libcontainer. Article.
Understand that I’m aware this is not accurate from a strict software engineering perspective but it should serve us well for the purpose of this blog post.
Lest people conflate VMs and containers and start thinking about deploying containers to bare metal, I want to point out that that is not a very good security policy. There are ways to get around the constraints imposed by containers just like it’s possible for those 5-year olds to (accidentally or on purpose) remove the magic pair of glasses. So at the very least, think of containers as a way to solve the application packaging solution very cleanly. No more of those dependency conflicts where one app requires version X of a library and another app requires version Y.
@markmaglana Context: I'm not talking about the Kernel features here, I'm talking about the tarballs of root filesystems shipping today.
— Kelsey Hightower (@kelseyhightower) May 5, 2015Docker
The analogy in the previous section gave a good enough overview of what Docker is in the context of containers. So let’s dive directly instead to some hands on. Provided you’ve already installed Docker in your system, you can execute:
$ docker run -t -i ubuntu:14.04 /bin/bash
Which tells docker to download a container image called ubuntu:14.04 from the
public Docker image repository and run bash
from inside it. Without options this will run bash and then exit immediately after
the bash process is done. The -t and -i option tells docker to attach a
psuedo-TTY session so that you can do something useful with it. When you hit
ENTER, you will see something similar to the following:
Unable to find image 'ubuntu:14.04' locally
Pulling repository ubuntu
07f8e8c5e660: Download complete
e9e06b06e14c: Download complete
a82efea989f9: Download complete
37bea4ee0c81: Download complete
Status: Downloaded newer image for ubuntu:14.04
root@9c005c9d9c16:/#
What just happened is that Docker downloaded a bunch of image diffs that, combined, creates the ubuntu:14.04 image that you asked for. Once you get to the prompt, you are inside bash in your container. Open another terminal and run:
$ docker ps
This will give you a list of running containers:
CONTAINER ID IMAGE COMMAND CREATED STATUS
9c005c9d9c16 ubuntu:14.04 "/bin/bash" 51 seconds ago Up 50 seconds
Go back to your container and install redis:
root@9c005c9d9c16:/# apt-get install nginx
The usual apt-get prompt will happen which will get you to a point where nginx gets installed inside the container. Once that completes, exit your container.
root@9c005c9d9c16:/# exit
exit
That kills your container but keeps its image on your host’s disk. You can still see it by running:
$ docker ps -a
Which will get you:
CONTAINER ID IMAGE COMMAND CREATED STATUS
9c005c9d9c16 ubuntu:14.04 "/bin/bash" About an hour ago Exited (0) 1 second
Alright, let’s pretend that installing nginx is all we need to do to our container. We can now commit the image and then push it to the public Docker image registry for world domination! NOTE that you can optionally push it to a private repo if world domination is not your thing.
$ docker commit 9c005c9d9c16 <USERNAME>/world_dominator:v1
8dde599a998311e3af20275676cc0c0943e6352a71518a6783b305cd3ff5a012
That created a new image called <USERNAME>/world_dominator:v1 and you’ll see it
listed with the command:
$ docker images
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
<USERNAME>/world_dominator v1 8dde599a9983 54 minutes ago 206.4 MB
ubuntu 14.04 07f8e8c5e660 6 days ago 188.3 MB
ubuntu 14.04.2 07f8e8c5e660 6 days ago 188.3 MB
At this point the image is still stored locally. Let’s push it to the public registry to finally realize world domination.
$ docker push <USERNAME>/world_dominator:v1
The push refers to a repository [<USERNAME>/world_dominator] (len: 1)
Sending image list
Pushing repository <USERNAME>/world_dominator (1 tags)
e9e06b06e14c: Image already pushed, skipping
a82efea989f9: Image already pushed, skipping
37bea4ee0c81: Image already pushed, skipping
07f8e8c5e660: Image already pushed, skipping
8dde599a9983: Image successfully pushed
Pushing tag for rev [8dde599a9983] on {https://cdn-registry-1.docker.io/v1/repositories/<USERNAME>/world_dominator/tags/v1}
BOOM.
{kind=link}

You might be thinking “Really?? That’s how you create a container?? Run from a base image, log in and manually install stuff??” Well sure you can do that all day if you like to live in the dark ages. If you want to keep up with the cool kids though, you should use Dockerfiles. These files codify how you want your container built. Now since it’s just a plain text file, you can also commit it with the rest of your code! Here’s an example Dockerfile for the official NGINX container.
Rocket (rkt)
Docker has, without a doubt, successfully brought containers to the mainstream. Since its initial announcement, it has grown from being a set of CLI tools + container runtime to a full platform that includes cloud servers, clustering, networking and so forth. For some, this may be attractive since they’ll have a one-stop-shop for anything containers. For others, this raises a big red vendor lock-in flag. The folks at CoreOS also had an issue with Docker’s proposed monolithic structure and preferred something more composable. Thus Rocket was born. I won’t duplicate what CoreOS has written well enough so I will just point you to the original rkt announcement.
My take on this is that I like where rkt is heading and appreciate that it uses
already existing tools like systemd-nspawn to implement the runtime rather than
roll its own the way Docker did with libcontainer. I also like the fact that
rkt adheres to the ACI standard for its image format. Having a common and stable
(or, at least, predictable) standard to build on top of allows developers to
focus on innovating instead of worrying about workarounds and conditionals.
Alright, that’s all I will say about container runtimes for now.
Kubernetes
Containers are great. You can package your application cleanly and be assured that it will run correctly wherever it will be deployed. So let’s say you’ve containerized your application. Making sure that your frontend is in one container, your API server is in another, and your database is in yet another. Now all you have to do is deploy multiple copies of each and stitch them together. Easy peasy, right?
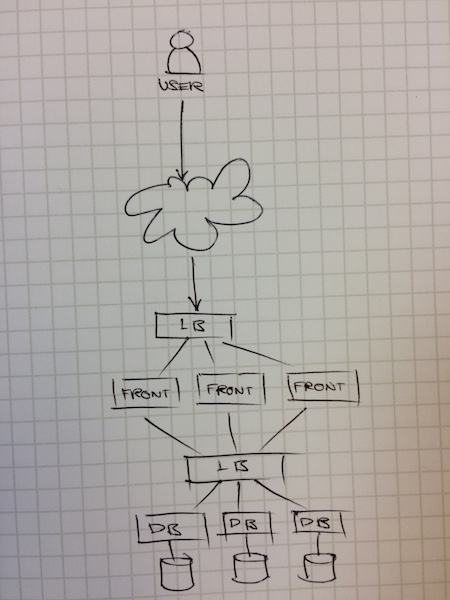
Not really. While you application packaging problem has been solved by containers, your deployment orchestration problem is not. How do you ensure that your containers know about each other on deploy? How will you ensure that, even when one of your containers die that your app will still be OK? What about when it’s time to upgrade your frontend?
Lucky for you some little company called Google had the same problem years back. They also were able to solve it internally long before Docker and rkt came into being. When they saw Docker’s rise in the mainstream, they decided it was time for the next iteration of Google container orchestration which would be publicly consumable. Thus Kubernetes was born.
The idea behind Kubernetes (or k8s for short) is that you’d just give it the desired state of your application (e.g. I want 3 instances of my frontend) and it will go off and deploy your app via Docker/rkt and ensure that your application stays in the state that you specified. It’s very powerful stuff and makes container scheduling/orchestration a whole lot easier.
I now point you to the first demonstration of Kubernetes.
Continuous Containerization
The Docker/rkt + k8s combination is great but there’s still a gap betwen writing
your code and giving it to k8s for deployment. Somewhere in there, somebody still
has to run docker build to containerize your app. No doubt it should be relatively
easy to automate via Jenkins if you already have one somewhere. If you don’t want
to be bothered with setting up Jenkins jobs though, you might want to look at
Quay.io. My notes from their presentation:
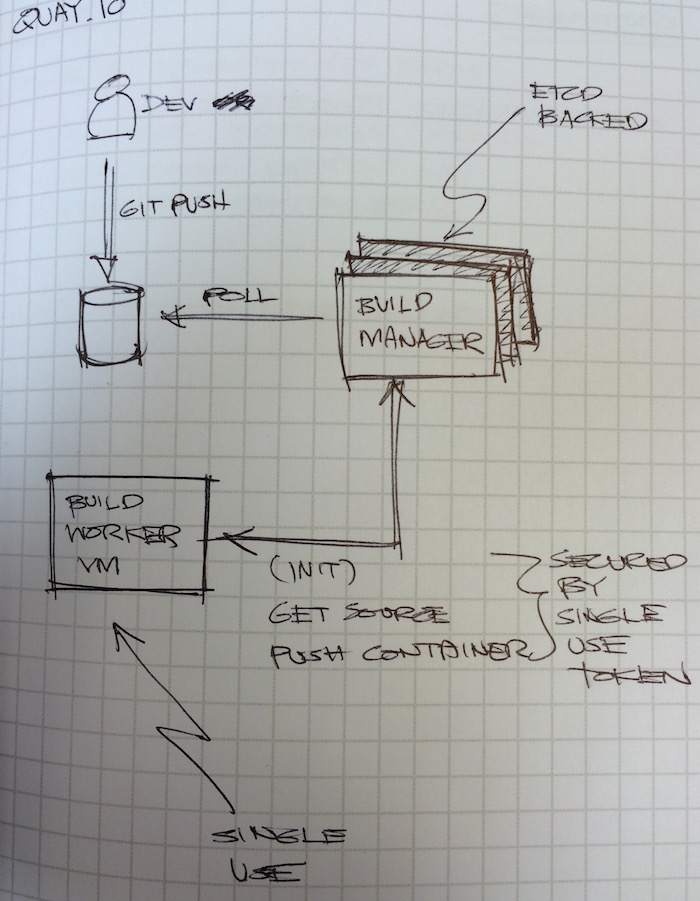
Yes, they’re basically a build and release service for containerized applications. I want to highlight a smart design that they incorporated into their service though. The problem with this kind of service is that they’d be running untrusted code in their build workers. To get around this security issue, they did a couple of things:
- Make the build workers single-use only. Once it’s done building the container image and has handed it off to the manager, it gets killed and never used again. Now what about response times? I’m sure they have an optimal queue of freshly booted workers just waiting to accept work.
- In case some rogue code actually takes over the build worker and prevents it from shutting down, it will not be able to interact with the manager since it only has access to a single-use security token that the manager invalidates at the end of the job. This is also likely on top of a security group setting that severly limits outgoing connections.
Continuous Containerization (local edition)
Here’s a handy tip that I picked up from one of the breakout sessions. During your normal dev workflow, you may (should) want a container build script continuously running in the background. If you’re running OS X, chances are you’re running that in a vagrant box since OS X doesn’t support Docker.
Your initial thought then might be to mount the local directory where your source files are into the Vagrant box or you might also do it the other way where you do an NFS share from the vagrant box to your local disk. From what I understand, neither options are optimal since it can slow down one or the other. Thus the speaker suggested that your IDE and the build script in the Vagrant box have their own local copy of the source and just rsync between the two.
I don’t know how much better that is or if it’s worth the trouble but I’m keeping a note of it here to come back to when I need it.

Debugging Containers
In a containerized world, you still want to be equipped with the right tools to understand what’s going on when things aren’t going as expected. Sure there is top, lsof and tcpdump. But what if you need a smoother and finer-grained control over how you inspect your system. That’s what sysdig is about. When this session started I wasn’t expecting much and in the first minute my reaction was that the tool provided a nice cleaner interface over existing tools. However, when the demo started to go through drilldowns starting from a top-like interface and ending up with HTTP headers and ENOENT error details while staying inside the sysdig, I was blown away. As if that was not enough the demo proceeded to the web based UI where the same drill-down feature is also available BUT with the effect of zooming in and out like Google Maps!
I’d say this was one of the more impressive presentations in the conference and that’s saying a lot considering all the other great presentations in the event. I’m definitely going to keep an eye on this tool for the future. You should too! Check out this sysdig example page.
Notable Stuff
There was a lot more happening in CoreOS Fest 2015 than this blog post can do justice. I learned a lot of useful things from it and I didn’t even get to go to all the breakout sessions! I just want to mention a few more items that I might end up writing more about in the future:
- The Update Framework - Learn how to secure your packages should you need to implement your own software update system.
- etcd - Distributedd key-value store. I should really pay more respect to this project here but others have written about it and anything I write will not add much value.
- Governor - PostgreSQL HA with etcd.
- systemd - The new PID 1.
- Cockroach DB - Touted as a DB that will likely survive a nuclear blast. :-)
- Project Calico - This project also deserves a blog post of its own but for now, how I understand it is that it can provide a way for DevOps to declaratively impose network security at the container level. I initially understood it as security groups for containers but that might be hugely inaccurate.